“Publish or Perish” is a common saying among scientists. But in order to publish, we must, after the experiments have been performed and the analysis done, write. Of course I enjoy writing, but it is extremely hard and painful. Literally painful. Not only it is very hard to come into the writing zone. Staying there is even harder when you stare at an empty page. This is the time when I procrastinate most: I check emails, repeate analyses, improve the format of plots, watch ted talks. You probably know what I’m talking about.
The hardest job, at least in my experience, is to start a manuscript — the first attempt to put down the first thousands words forming a concise text. Over the years I came to realize that there is no such thing as a perfect first draft. Neither a second. Furthermore, I came up with several techniques in order to overcome the first painful hours with filling pages. Here, I would like to share some of my insights with you. The techniques are based on the idea to focus on one problem at one time. Some of these things seem to be very obvious, but believe me, repetition is the key to proficiency.
The baseline of a successfull writing start is preparation
Whatever you are doing, writing a term paper or a journal paper, you are presenting knowledge for a reader. Before you put any words to paper (or your screen) and formulate sentences, you need to know what you are talking about. Whenever you want to start writing but have only vague ideas about what to write, you will fail.That is the simple truth. Depending on what part of your paper you want to write, you need to prepare differently.
For an introduction, you need to do the research on your topic, find papers, read them, skim through the results and discussion in order to not only report the background of your paper but also formulate precise hypotheses.
For a results section, you need to have the results of your analysis (be it analytical, statistical, or whatever).
For a discussion, you need to have a results section, otherwise there is nothing to discuss. Also, start working on the discussion only when you have finished the text on the introduction and the results.
Technique 1: Keywords
Never, I repeat, never start a new text by trying to write correctly formulated sentences. Embarking on a writing journey with correctly formulated sentences is the road to procrastination and frustration.
Do you remember what the aim of a paper is? Right, to provide knowledge to your reader. However, when you start writing a paper by trying to formulate complete sentences, you shift the focus of your task from transferring knowledge to finding the appropriate words and syntactic structure. Do not waste your energy on such a thing. Start with writing down your knowledge in the form of keywords. The keywords need to convey most of your knowledge, but it is not be important which exact words you use. Again, how you perform this task depends on the section you are writing.
Introduction
Write a keyword-based summary of the papers you read. Provide a short phrase for each of the topics: Who has done it, what was the point, what was the method (experiment, analysis, etc.), what was the finding, and what was the interpretation? Write down your hypotheses.
Results
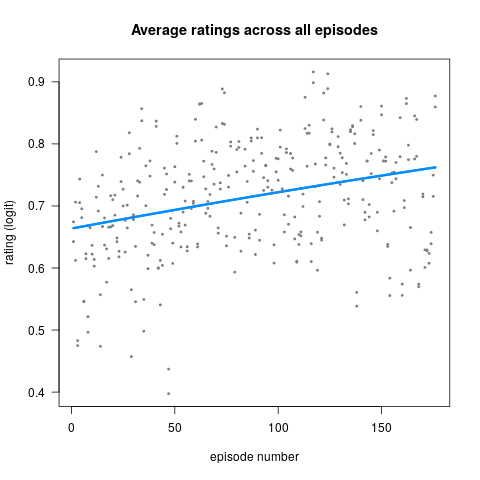
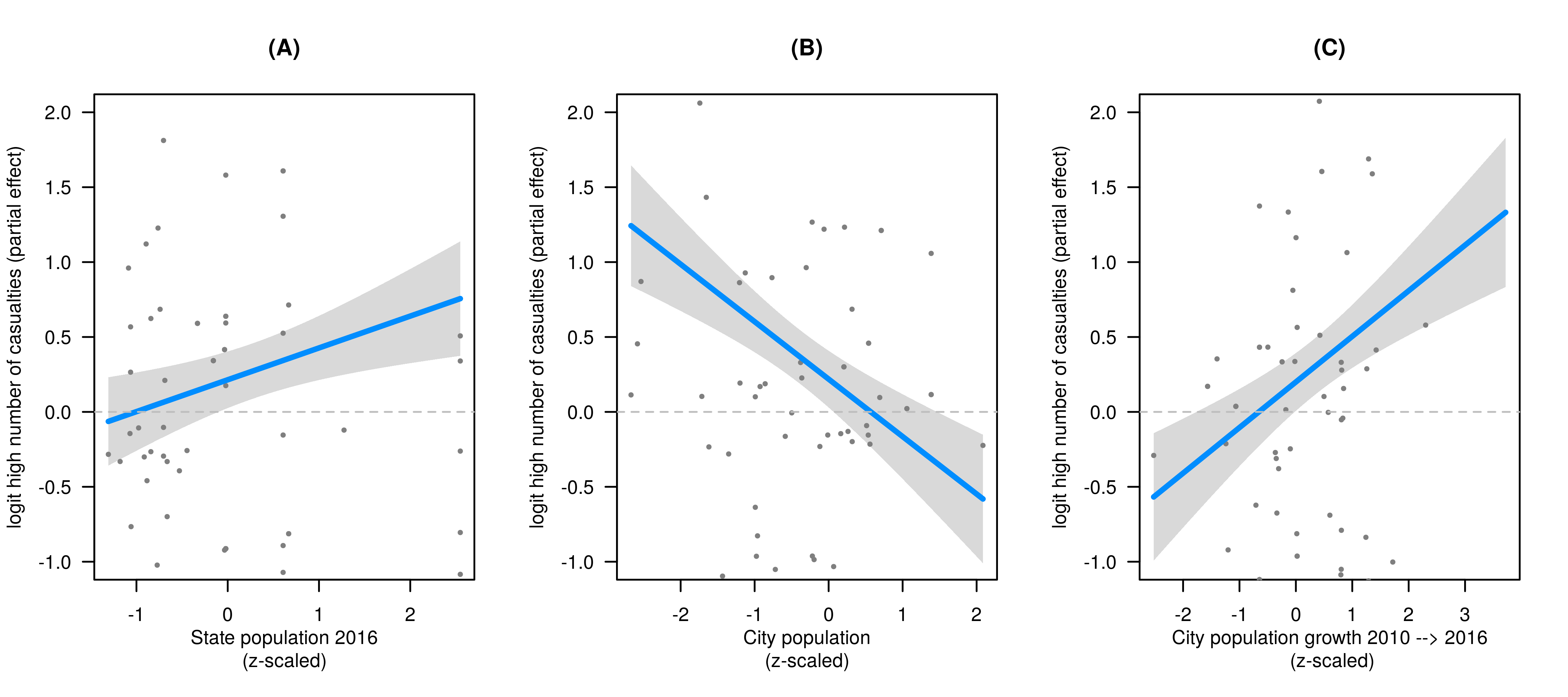
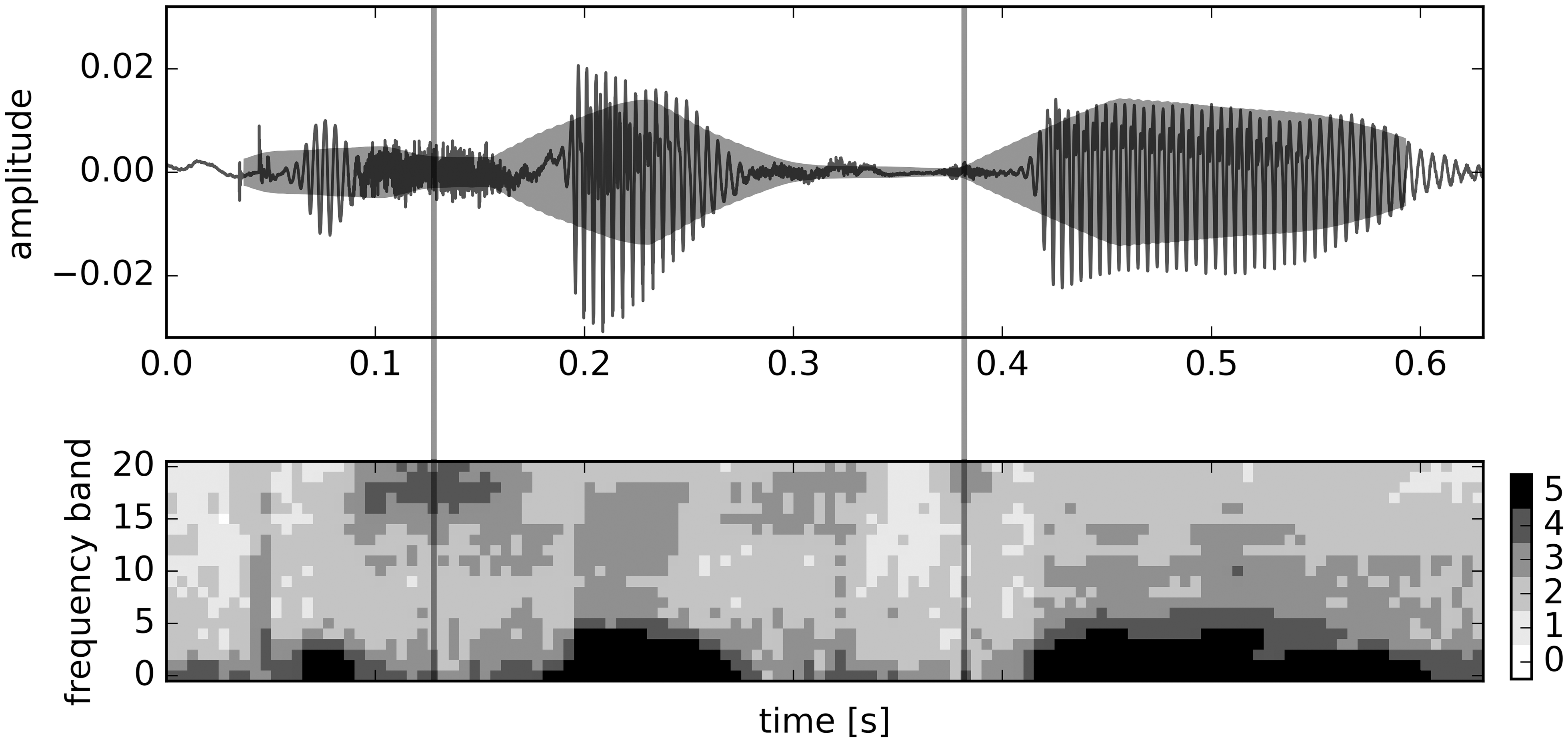
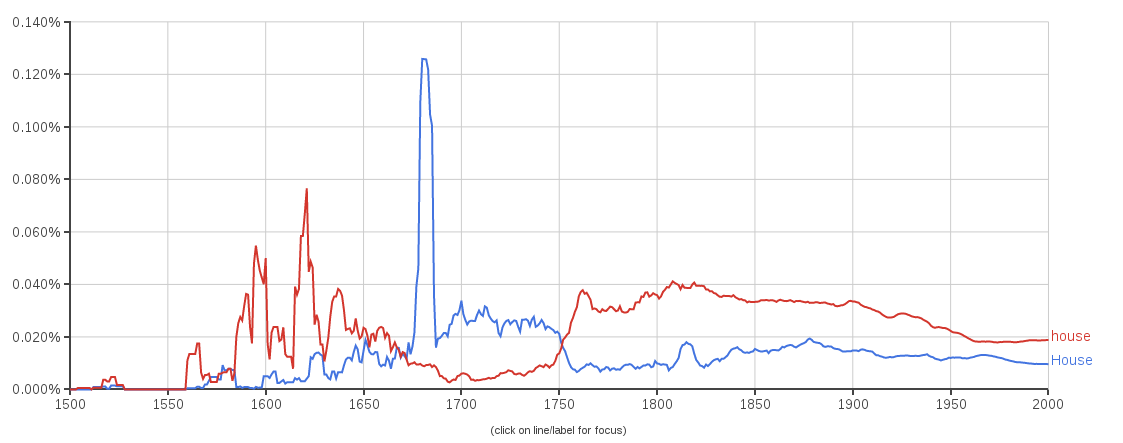
Start putting keywords down about your analysis. If you have a figure, describe the figure. If you have a summary table for a regression (ANOVA, ANCOVA, LMER, GAMM, BAYES, etc.), describe your effects using general language (e.g. “In level A, Y was slower than in level B”, “An increase in Y was associated with an increase in X”). Do not waste your time and your energy with exact numbers. This is the first draft. You need to regard your first draft as the placeholder for exact numbers, precise formulations, and sparkling-from-intelligence metaphors.
Discussion
You have probably guessed it already: Start with keywords. Reread your introduction and results and write keywords about your main findings. Write keywords about how they are in line or differ from the literature you consulted. Write keywords about how you interpret your results. Write keywords about the problems you encountered.
Technique 2: Talk to an audience
The next step seems easy: take all these keywords and formulate sentences out of them. However, this is still hard to do, to take all those unconnected and sometimes contradictory pieces of knowledge and bind them together into a coherent and readable text. When you begin to write right from the start, you might end up struggling with correct formulations, nice words and nice syntactic structures, instead of doing what needs to be done: Formulate a text. Now, I came up with two possibilities in how to circumvent this struggle.
The first possibility is to tell the things you want to write to a friend. Tell him or her about your problem, what you have done and what results you found. The second possibility is to dictate and record this onto a recording device. Or even better, do both. If you don’t have anyone at hand or don’t want to bore your friends with your scientific ideas, take your recording device and go on a walk (we need to do that more often, anyways).
Here is what happens when you start talking: Instead of struggling to find cool sounding words and sentences, your brain will put all the effort it takes to create a coherent and understandable version of what you want to say so that your audience understands your message. Humans communicate, humans try to put sense into their messages. Use that power.
Once you have recorded your text, transcribe it (e.g. using transcription software such as F4). And voilà, you have your text. You will be surprised, how much you have to talk about your topic all of a sudden. Furthermore, during transcription, you start to think whether what you said actually makes sense. However, do not rewrite your transcription. Literally put down every word you have spoken.
Technique 3: Rewrite
Now you have something to work on. Now, once you have a text with complete sentences, you can start to invest your effort into cool words and nice sentences. You do not need to focus on remembering the knowledge you want to include into your paper; you do not need to focus on performing an analysis; rather, you can focus and invest your all of your mental energy on correcting your text. And the surprising thing is: correcting and rewriting is a lot easier than writing down new sentences.
This is the time where you start including precise information about your analysis, i.e. exact numbers such as slopes, t- and p-values, and everything which is connected to your analysis. This is also the time when you can redo your research about questions which came up during the first draft.
Technique 4: Write regularly
OK, this is not my technique. It is from “How to write a lot” by Paul Silvia. He suggests, and I can only recommend this, to make room for writing every day. At least one our. It is not important whether you do this after waking up, or before going to bed. But save one hour (or two if you are in the mood) only for writing. Turn of your mobile phone, your internet connection, shut your door, turn off your TV, and start to write. Silvia shows data that this is the only technique by which you can make progress. If you wait for the muse to kiss you, you can keep on waiting forever. You need to sit down and write. Every day!
Technique 5: Perform different tasks at different places
Sometime I heard that Walt Disney used three different rooms for his work – one room for the coming ip with ideas, one room for writing and one room for drawing. Whether this story is true or not, it makes perfect sense to adapt this technique for writing papers.
A short excursion: Think about your getting up habits? What is the order of going to the bathroom, making coffee (or tee), brushing your teeth, etc. Probably it is the same every day. And try to recall how unhappy you are, when this order is broken. The reason for this is that we have habits how things have to happen. Make it habit to write every day! Make it a habit to think about problems in one place (e.g. in the shower, on your way home, on your bike, while exercising), to write down keywords in another place (e.g. in the library, the pub, the cool coffee house next door), to rewrite in your office (or at home, if you cannot work in the office).
Furthermore, get habits for starting to write. For example, I always drink a cup of coffee before I start to write. It works like a mental switch.
Make it a habit to plan what you want to do in your writing hour. For example: Write 1000 words. Rewrite one chapter.
Make it a habit to reward yourself for work you have done. Not only, it makes you happy having done the work you planned. No, it makes you happy that you (finally) can watch the YouTube video you were eager to see. Rewarding yourself keeps you from procrastinating, as you change your habit from watching YouTube for procrastination to watching YouTube for reward.
Technique 6: Take your time
Rome was not built in one day. Neither is written a scientific paper. Take your time. After having written your first and second draft, leave the manuscript alone for a couple of days (sometimes even a week or two). Work on other things. In this way you clear your head from the current project, allowing oyu to reread your manuscript more critically, to find errors in the writing, the structure and the argumentation. Do this at least twice before you pass your manuscript on to someone else.
Good writing!